
21. November 2024 By Dominik Táskai
Building a Modern Analytics Architecture: Data Warehousing on AWS
Designing the Data Pipeline
Creating a resilient data pipeline on AWS is the base of any modern, cloud-based, data warehousing architecture. The process involves ingesting, transforming, and storing large volumes of data from multiple different sources (REST API, Message Queues, CSV files) before it’s ready for analysis.
Data Ingestion
To start, data must be ingested from a variety of sources— relational and non-relational databases, on-premises data centers, or real-time streaming data from message queues. AWS Lambda, Glue, and DMS are just some of the popular choices for ingesting and loading data. For real-time data ingestion needs, Kinesis provides a seamless way to handle streaming data. The ingested raw data is then stored in S3 or processed in-flight with Kinesis Transformation Lambdas and then saved in S3, which acts as the central storage space for our data warehouse.

Figure 1: Data Ingestion Options
Data Transformation
Once data is ingested and safely stored in S3, it must be transformed or cleaned to make it suitable for analysis. Glue, a managed ETL service, simplifies the Extract, Transform, Load (ETL) process by allowing you to clean, format, and prepare data efficiently with the use of Apache Spark jobs for example. This step is important for removing or masking unneeded data attributes (PII for example) or enriching the data with attributes coming from other sources. Glue also offers a visual ETL environment in the form of Glue Studio, which makes it easier even for analysts to build complex data workflows with minimal code.
Data Warehousing with Redshift
Amazon Redshift is a data warehousing solution provided by AWS. It is optimized for handling large-scale analytics purposes. Redshift has the tools needed to manage petabyte-scale data with fast query performance for analytics workloads. Let’s check deeper what setting up, modeling, and optimizing data storage and querying within Amazon Redshift looks like.
Setting Up Redshift
Redshift clusters are based on user-picked instances and you can choose from several instance types, depending on your performance and cost requirements. RA3 nodes are recommended because they separate compute and storage, allowing for scalable and cost-effective usage as in the need of more storage you don’t have to compromise for more or less computing capacities. Setting up a cluster by yourself might be overwhelming so thankfully AWS provides a guided instance selector to make sure you get the most cost-effective setup possible.

Figure 2: Redshift Cluster Node Configurator
Data Modeling
The Star and the Snowflake Schema are often recommended and Redshift supports both for data modeling. In the Star Schema, you have a central fact table that contains the data and multiple dimension tables that will describe the attributes associated with the fact data. The Snowflake Schema normalizes the dimension tables, and it is worth mentioning that Redshift has great performance with both schemas, but the Star Schema is often simpler to manage and preferred for data modeling optimization.
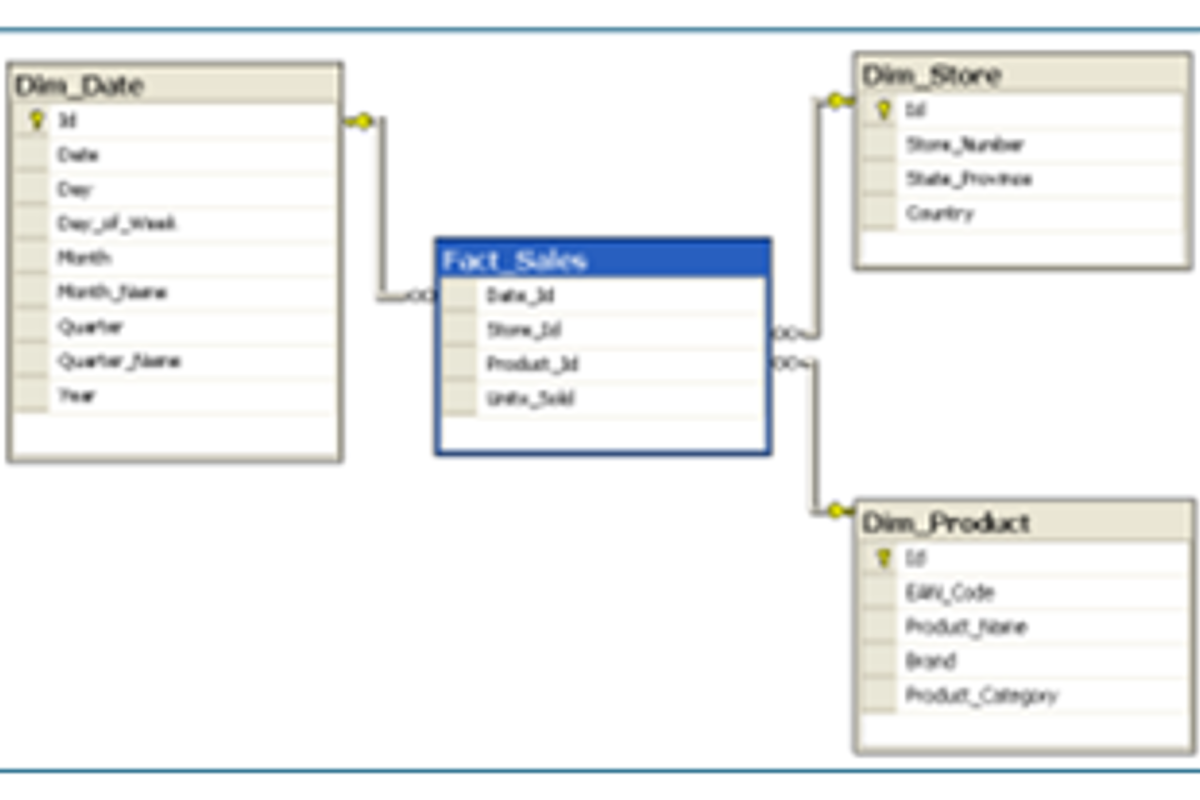
Figure 3: Star Schema (Wikipedia)
Performance Tuning
Sort and Distribution Keys
When data is loaded into a table for the first time, the rows are stored based on the sort key that we chose. Queries use the sort keys to benefit from faster query times as the information about the sort keys is passed to the query planner, which in turn can be used to plan how the requested data should be accessed from the storage.
Distribution keys control how data is distributed across the nodes of our previously created Redshift cluster. Choosing the right distribution style (even, key-based, or all) is also important it can minimize data movement across nodes, improving query speed yet again.
Automatic Vacuuming
To keep tables efficient and reduce unused storage, Redshift requires periodic maintenance. Vacuuming is an operation that reclaims storage by removing deleted data, Redshift of course provides automated vacuuming between specified intervals.
Data Unload to S3
Data that is not frequently accessed in the warehouse but is still required due to archival or compliance reasons, can be unloaded to S3, where in combination with S3 Storage Classes, it can be stored cost-effectively. This operation allows you to remove infrequently accessed data, while still having the ability to query it with Redshift Spectrum when required.
Conclusion
In this introductory part, we overviewed how we can get the data onto our newly built data warehouse in our preferred format, utilizing AWS Glue, Lambda, and Kinesis, and explained how we can store it durably inside S3, and move it onto our analytics platform in the form of AWS Redshift, while also taking a look at some optimization techniques.
In the next part, we will take a look at the security and compliance options and how we can perform data analytics in Redshift, while also peeking at the data visualization services provided by AWS.

Category: |
|
Tags: |
Amazon Web Services (AWS) |